
- News : De la search IA payante chez Google ?
- Quick hack : Faites vérifier un contrat par ChatGPT.
- Tendance : La ruée vers la donnée, conséquence inattendue du boom de l'IA.
« La seule chose qui nous empêche d'être aussi performants que ChatGPT, c'est littéralement le volume de données. »
Pour expliquer le retard des modèles de Meta sur ceux d'OpenAI, Nick Grudin, VP Global Partnership & Content, a pointé du doigt le manque de data, et a sous-entendu qu'OpenAI avait exploité des données non libres de droit pour entraîner ses modèles et prendre une longueur d'avance.
En coulisses, c'est une véritable ruée vers la donnée qui a lieu parmi les développeurs de grands modèles IA. Et ces derniers ne sont pas à court de stratagèmes plus ou moins avouables.
L'enjeu ? Réunir des volumes faramineux de contenu pour entraîner le futur modèle le plus performant du marché, et rafler la mise.
Découvrez comment la data est devenu le nouvel or de l'âge de l'IA dans cette édition.
Sane de Upmynt 💙
Les news chaudes 🔥
🔍 Search IA payante. C'est ce que Google considère, contre toute attente (toutes les fonctionnalités clés offertes par le géant ont toujours été gratuites).
Cette décision révèle autant une volonté de Google de protéger son principal business (la recherche classique) qu'une difficulté latente à monétiser l'IA, ou en tout cas à la rentabiliser, étant donné son énorme coût de fonctionnement.
« La recherche Google imprime de l'argent. L’IA générative brûle de l’argent. Que se passe-t-il lorsqu'une force imparable frappe un objet immobile ? » - Futurism
👁 Publicité IA. Perplexity veut vendre des pubs. Après avoir notamment levé $4Mds auprès d'Amazon, le moteur de recherche IA, qui génère des réponses basées sur des résultats extraits du web, a besoin de cash.
Lorsque le moteur répond à un utilisateur, Perplexity suggère ensuite d'autres questions sur le même thème. Ces questions liées représentent 40% de l'usage de Perplexity, les utilisateurs continuant volontiers leur exploration en cliquant sur celles-ci. Et c'est là que des pubs pourraient être insérées.
👩🏻❤️👨🏽 IA biaisée, épisode 432. Nouvelle polémique en vue : le générateur d'images de Meta (dispo seulement aux US) rechigne à représenter des couples mixtes.
Ainsi, malgré des prompts décrivant une femme asiatique avec un homme blanc, le générateur s'est borné à représenter systématiquement des couples entièrement asiatiques.
Pour ne rien arranger, l'homme a été systématiquement représenté plus âgé que la femme… Y a du boulot chez Meta.
✨ Édition de visuels. ChatGPT vous permet désormais d'éditer les visuels générés sans quitter le chat en cours.
La manipulation, consistant à sélectionner avec un pinceau la zone du visuel à modifier, est simple comme bonjour.
Communauté 🦊
Cet espace est le vôtre. Recrutement, ressource à partager, demande d'aide, question. Répondez à cet email pour y apparaître.
- Job à saisir
TF1 recherche un chef de projet Innovation/IA, pour identifier les solutions IA adaptés à l'activité du groupe et accompagner leur expérimentation puis leur implémentation. Poste basé à Boulogne-Billancourt.
Quick hack ⚡️ Faites vérifier un contrat par ChatGPT
Si ChatGPT ne peut se substituer à un juriste (notamment parce qu'il est sujet aux hallucinations), il peut malgré tout vous "dépanner" sur certains usages liés au droit.
ChatGPT peut ainsi vous aider à examiner un contrat, et identifier des clauses non standards, des risques potentiels ou des points nécessitant une attention particulière.
Voici le prompt magique pour un résultat optimal :
Voici un contrat qui vise à [décrire l'objectif du contrat, par exemple "fournir des services logiciels", "réaliser un projet de construction", "offrir des conseils en gestion", etc]. Analyse-le, en te concentrant sur ces 3 aspects :1- Identification des points clés : Détaille les objectifs principaux du contrat, les parties impliquées, la durée, et tout autre élément essentiel pour comprendre le contrat.
2. Divergences par rapport aux pratiques habituelles : Compare les clauses de ce contrat avec les modèles standards dans le domaine concerné. Souligne les clauses non standard ou inhabituelles, explique en quoi elles diffèrent des pratiques habituelles et discute des implications potentielles de ces divergences.
3- Évaluation des risques potentiels : Identifie et explique les clauses ou termes qui pourraient présenter des risques pour l'une des parties, en précisant la nature de ces risques et leurs conséquences potentielles.
Tendance 🌈 La ruée vers la donnée, conséquence inattendue du boom de l'IA
Le boom de l'IA est synonyme de plusieurs pénuries : celle des microprocesseurs (surtout les GPU de Nvidia), de l'électricité (bientôt), des talents, et, de manière plus inattendue, de la data.
📊 Le marché de la vente de données est en pleine explosion, estimé aujourd'hui à $2,5Mds, mais voué à dépasser les $30Mds d'ici une décennie, soit un beau x12 (source : Business Research Insights).
Une pénurie, vraiment ?
L'internet regorge de données, croirait-on. Certes, mais :
- Les modèles ont besoin de données de qualitay, pas juste quelques tweets écrits par des décérébrés complotistes (« je ne contracte pas » résonne encore dans ma tête).
- En théorie, les données en question doivent être libres de droit, ce qui réduit considérablement le réservoir de data disponible.
- De plus en plus de sites et médias ont bloqué l'accès à leur contenu, pour le protéger des extracteurs de données opérés par les développeurs des LLM. Résultat : ce n'est plus la fête du slip de la data.
- Pour continuer à s'améliorer, les modèles doivent digérer des quantités de données toujours plus massives pendant leur entraînement. Une étude de la Johns Hopkins University publiée en 2020 fait autorité en la matière. Sa conclusion ? Plus il y a de données pour entraîner un LLM, meilleures sont ses performances.
Des modèles de plus en plus gourmands
📊 Rendez vous compte : le "vieux" GPT-3 d’OpenAI, sorti en 2020, a été entraîné sur 500 Mds de tokens (essentiellement des mots ou des morceaux de mots).
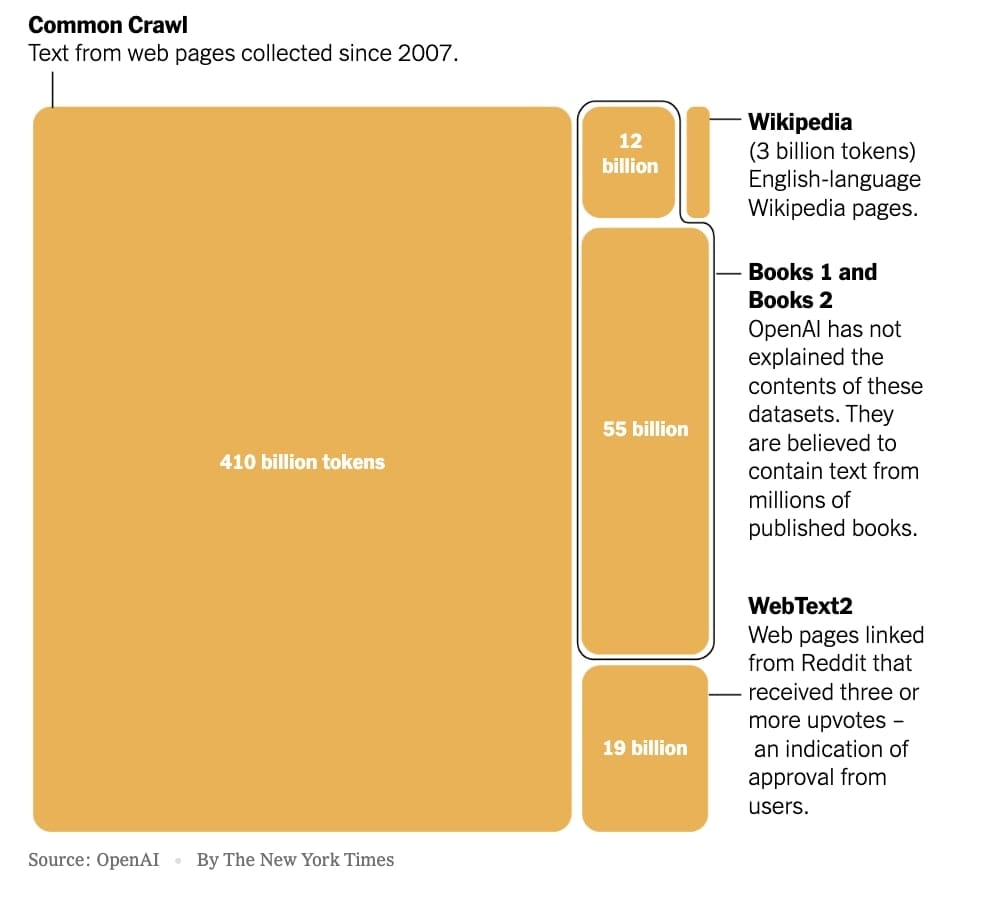
Et on estime que les derniers grands modèles de langage (LLM) ont quant à eux nécessité bien plus.
Plus précisément, GPT-4 aurait été entraîné avec 12 billions de tokens, soit 12.000 Mds de tokens. C'est 24x plus que GPT-3.
Et GPT-5 ? Le modèle nécessiterait entre 60 et 100 billions de tokens. N'en jetez plus !
⏰ Résultat : si les développeurs ont réussi à trouver tant que bien mal tous les textes nécessaires, des experts alertent sur une demande supérieure à l'offre totale (= tous les textes de qualité jamais générés par l'homme) en 2028. Le compte à rebours a commencé !
Côté image, les développeurs n'ont pas divulgué les volumes exactes de clichés digérés, mais le PDG de Midjourney avait évoqué « plusieurs centaines de millions d'images » (notamment pour justifier qu'il était impossible de négocier les droits pour tant de fichiers).
Les manœuvres obscures des développeurs
Pour trouver cette précieuse donnée, les développeurs ne reculent devant rien, ou presque :
- Des transcriptions de vidéos YouTube (générés grâce à l'IA audio "Whisper"), auraient été utilisées par OpenAI pour GPT-4, et la stratégie serait toujours utilisée avec l'entraînement en cours de GPT-5 (sans l'accord de Google, et encore moins des créateurs de contenu).
- Google ouvre les vannes sur le "contexte" des requêtes, c'est-à-dire la taille des prompts. Il devient donc possible sur Gemini 1.5 d'attacher des PDF d'une taille équivalente à plusieurs livres (1M de tokens). Mais Google est soupçonné de vouloir utiliser ces documents chargés par les utilisateurs pour entraîner ses futurs modèles.
- Meta se targue de disposer d'un immense réservoirs de textes et images grâce à Facebook et Instagram, ce qui leur offre un avantage décisif par rapport à la compétition (qui doit dépendre des bases de données publiques, bien moins riches). Mais cela ne serait toujours pas suffisant.
Le NY Times vient tout juste de révéler que chez Meta, dirigeants, avocats et ingénieurs auraient discuté l'année dernière du rachat de la maison d'édition Simon & Schuster pour obtenir les droits sur des ouvrages entiers.
Ils auraient également discuté de la collecte de données protégées par le droit d’auteur sur Internet, même si cela impliquait des poursuites judiciaires. Négocier des licences avec les éditeurs, les artistes, les musiciens prendrait trop de temps…


